Team

Academic Staff
Carina Liebers, M.Sc.
- Room:
- S-L 406
- Phone:
- +49 201 18-33754
- Email:
- carina.liebers (at) uni-due.de
- Homepage:
- https://carina-liebers.de/
Publications:
- Liebers, Carina; Pfützenreuter, Niklas; Auda, Jonas; Gruenefeld, Uwe; Schneegass, Stefan: "Computer, Generate!” – Investigating User Controlled Generation of Immersive Virtual Environments. In: HHAI 2024: Hybrid Human AI Systems for the Social Good. IOS Press, Malmö, 2024, p. 213-227. doi:10.3233/FAIA240196AbstractPDF Details Full textCitation
For immersive experiences such as virtual reality, explorable worlds are often fundamental. Generative artificial intelligence looks promising to accelerate the creation of such environments. However, it remains unclear how existing interaction modalities can support user-centered world generation and how users remain in control of the process. Thus, in this paper, we present a virtual reality application to generate virtual environments and compare three common interaction modalities (voice, controller, and hands) in a pre-study (N = 18), revealing a combination of initial voice input and continued controller manipulation as best suitable. We then investigate three levels of process control (all-at-once, creation-before-manipulation, and step-by-step) in a user study (N = 27). Our results show that although all-at-once reduced the number of object manipulations, participants felt more in control when using the step-by-step approach.
- Liebers, Carina; Megarajan, Pranav; Auda, Jonas; Stratmann, Tim C; Pfingsthorn, Max; Gruenefeld, Uwe; Schneegass, Stefan: Keep the Human in the Loop: Arguments for Human Assistance in the Synthesis of Simulation Data for Robot Training. In: Multimodal Technologies and Interaction, Vol8 (2024), p. 18. doi:10.3390/mti8030018AbstractPDF Details Full textCitation
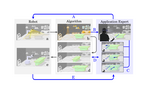
Robot training often takes place in simulated environments, particularly with reinforcement learning. Therefore, multiple training environments are generated using domain randomization to ensure transferability to real-world applications and compensate for unknown real-world states. We propose improving domain randomization by involving human application experts in various stages of the training process. Experts can provide valuable judgments on simulation realism, identify missing properties, and verify robot execution. Our human-in-the-loop workflow describes how they can enhance the process in five stages: validating and improving real-world scans, correcting virtual representations, specifying application-specific object properties, verifying and influencing simulation environment generation, and verifying robot training. We outline examples and highlight research opportunities. Furthermore, we present a case study in which we implemented different prototypes, demonstrating the potential of human experts in the given stages. Our early insights indicate that human input can benefit robot training at different stages.
- Liebers, Carina; Pfützenreuter, Niklas; Prochazka, Marvin; Megarajan, Pranav; Furuno, Eike; Löber, Jan; Stratmann, Tim C.; Auda, Jonas; Degraen, Donald; Gruenefeld, Uwe; Schneegass, Stefan: Look Over Here! Comparing Interaction Methods for User-Assisted Remote Scene Reconstruction. In: Extended Abstracts of the 2024 CHI Conference on Human Factors in Computing Systems. Association for Computing Machinery, New York, NY, USA, 2024. doi:10.1145/3613905.3650982AbstractPDF Details Citation
Detailed digital representations of physical scenes are key in many cases, such as historical site preservation or hazardous area inspection. To automate the capturing process, robots or drones mounted with sensors can algorithmically record the environment from different viewpoints. However, environmental complexities often lead to incomplete captures. We believe humans can support scene capture as their contextual understanding enables easy identification of missing areas and recording errors. Therefore, they need to perceive the recordings and suggest new sensor poses. In this work, we compare two human-centric approaches in Virtual Reality for scene reconstruction through the teleoperation of a remote robot arm, i.e., directly providing sensor poses (direct method) or specifying missing areas in the scans (indirect method). Our results show that directly providing sensor poses leads to higher efficiency and user experience. In future work, we aim to compare the quality of human assistance to automatic approaches.
- Liebers, Carina; Prochazka, Marvin; Pfützenreuter, Niklas; Liebers, Jonathan; Auda, Jonas; Gruenefeld, Uwe; Schneegass, Stefan: Pointing It out! Comparing Manual Segmentation of 3D Point Clouds between Desktop, Tablet, and Virtual Reality. In: International Journal of Human–Computer Interaction (2023), p. 1-15. doi:10.1080/10447318.2023.2238945AbstractPDF Details Full textCitation

Scanning everyday objects with depth sensors is the state-of-the-art approach to generating point clouds for realistic 3D representations. However, the resulting point cloud data suffers from outliers and contains irrelevant data from neighboring objects. To obtain only the desired 3D representation, additional manual segmentation steps are required. In this paper, we compare three different technology classes as independent variables (desktop vs. tablet vs. virtual reality) in a within-subject user study (N = 18) to understand their effectiveness and efficiency for such segmentation tasks. We found that desktop and tablet still outperform virtual reality regarding task completion times, while we could not find a significant difference between them in the effectiveness of the segmentation. In the post hoc interviews, participants preferred the desktop due to its familiarity and temporal efficiency and virtual reality due to its given three-dimensional representation.
- Abdrabou, Yasmeen; Rivu, Sheikh Radiah; Ammar, Tarek; Liebers, Jonathan; Saad, Alia; Liebers, Carina; Gruenefeld, Uwe; Knierim, Pascal; Khamis, Mohamed; Makela, Ville; Schneegass, Stefan: Understanding Shoulder Surfer Behavior and Attack Patterns Using Virtual Reality. In: Proceedings of the 2022 International Conference on Advanced Visual Interfaces, Vol2022 (2023), p. 1-9. doi:10.1145/3531073.3531106PDF Details Full textCitation
- Liebers, Carina; Agarwal, Shivam; Beck, Fabian: CohExplore: Visually Supporting Students in Exploring Text Cohesion. In: Gillmann, Christina; Krone, Michael; Lenti, Simone (Ed.): EuroVis 2023 - Posters. The Eurographics Association, 2023. doi:10.2312/evp.20231058AbstractPDF Details Citation
A cohesive text allows readers to follow the described ideas and events. Exploring cohesion in text might aid students enhancing their academic writing. We introduce CohExplore, which promotes exploring and reflecting on cohesion of a given text by visualizing computed cohesion related metrics on an overview and detailed level. Detected topics are color-coded, semantic similarity is shown via lines, while connectives and co-references in a paragraph are encoded using text decoration. Demonstrating the system, we share insights about a student-authored text.
- Liebers, Carina; Agarwal, Shivam; Krug, Maximilian; Pitsch, Karola; Beck, Fabian: VisCoMET: Visually Analyzing Team Collaboration in Medical Emergency Trainings. In: Computer Graphics Forum (2023). doi:10.1111/cgf.14819AbstractPDF Details Citation
Handling emergencies requires efficient and effective collaboration of medical professionals. To analyze their performance, in an application study, we have developed VisCoMET, a visual analytics approach displaying interactions of healthcare personnel in a triage training of a mass casualty incident. The application scenario stems from social interaction research, where the collaboration of teams is studied from different perspectives. We integrate recorded annotations from multiple sources, such as recorded videos of the sessions, transcribed communication, and eye-tracking information. For each session, an informationrich timeline visualizes events across these different channels, specifically highlighting interactions between the team members. We provide algorithmic support to identify frequent event patterns and to search for user-defined event sequences. Comparing different teams, an overview visualization aggregates each training session in a visual glyph as a node, connected to similar sessions through edges. An application example shows the usage of the approach in the comparative analysis of triage training sessions, where multiple teams encountered the same scene, and highlights discovered insights. The approach was evaluated through feedback from visualization and social interaction experts. The results show that the approach supports reflecting on teams’ performance by exploratory analysis of collaboration behavior while particularly enabling the comparison of triage training sessions.
- Abdrabou, Yasmeen; Rivu, Radiah; Ammar, Tarek; Liebers, Jonathan; Saad, Alia; Liebers, Carina; Gruenefeld, Uwe; Knierim, Pascal; Khamis, Mohamed; Mäkelä, Ville; Schneegass, Stefan; Alt, Florian: Understanding Shoulder Surfer Behavior Using Virtual Reality. In: Proceedings of the IEEE conference on Virtual Reality and 3D User Interfaces (IEEE VR). IEEE, Christchurch, New Zealand, 2022. Abstract Details Citation
We explore how attackers behave during shoulder surfing. Unfortunately, such behavior is challenging to study as it is often opportunistic and can occur wherever potential attackers can observe other people’s private screens. Therefore, we investigate shoulder surfing using virtual reality (VR). We recruited 24 participants and observed their behavior in two virtual waiting scenarios: at a bus stop and in an open office space. In both scenarios, avatars interacted with private screens displaying different content, thus providing opportunities for shoulder surfing. From the results, we derive an understanding of factors influencing shoulder surfing behavior.
- Latif, Shahid; Agarwal, Shivam; Gottschalk, Simon; Chrosch, Carina; Feit, Felix; Jahn, Johannes; Braun, Tobias; Tchenko, Yanick Christian; Demidova, Elena; Beck, Fabian: Visually Connecting Historical Figures Through Event Knowledge Graphs. In: 2021 IEEE Visualization Conference (VIS) - Short Papers. IEEE, 2021. doi:10.1109/VIS49827.2021.9623313Abstract Details Citation

Knowledge graphs store information about historical figures and their relationships indirectly through shared events. We developed a visualization system, VisKonnect, for analyzing the intertwined lives of historical figures based on the events they participated in. A user’s query is parsed for identifying named entities, and related data is retrieved from an event knowledge graph. While a short textual answer to the query is generated using the GPT-3 language model, various linked visualizations provide context, display additional information related to the query, and allow exploration.